Contents
- 1 Ж░ювЁљ
- 2 ВъљвБї ВѕўВДЉЖ│╝ Вцђв╣ё(Data Collection & Preparation)
- 3 ЖИ░ВѕаьєхЖ│ё(Descriptive Statistics)
- 4 ьЃљВЃЅВаЂ вЇ░ВЮ┤ьё░ вХёВёЮ(Exploratory Data Analysis)
- 5 ВХћВаЋ(Estimation)
- 6 Ж░ђВёц Ж▓ђВаЋ(Hypothesis Testing)
- 7 ьџїЖиђ(Regression)
- 8 вХёвЦў(Classification)
- 9 Жх░ВДЉ(Clustering)
- 10 ВІюЖ░ЂьЎћ
- 11 Вёюв╣ёВіц
- 12 В░ИЖ│аВъљвБї
ВъЉВё▒ВцЉ...
PythonВю╝вАю ьЋ┤в│┤вацЖ│авіћ ьЋўЖ│а ВъѕвіћвЇ░.. ВЋёВДЂЖ╣їВДђ RВЮ┤ ьЏеВћг ьјИьЋювІц.. ВЋё.. ьЋўЖИ░ ВІФвІц..
PythonВю╝вАю ьЋ┤в│┤вацЖ│авіћ ьЋўЖ│а ВъѕвіћвЇ░.. ВЋёВДЂЖ╣їВДђ RВЮ┤ ьЏеВћг ьјИьЋювІц.. ВЋё.. ьЋўЖИ░ ВІФвІц..
вІцВЮї ЖиИвд╝ВЮђ Ж░ювъхВаЂВЮИ вЇ░ВЮ┤ьё░ вХёВёЮВЮў ьЮљвдёВЮё в│┤ВЌгВцђвІц. ьєхЖ│ёВЎђ веИВІа вЪгвІЮВЮў Ж▓йЖ│ёЖ░ђ вфеьўИьЋўЖ│а вХёвфЁьъѕ ЖхљВДЉьЋЕ[1]ВЮ┤ ВъѕВДђвДї,
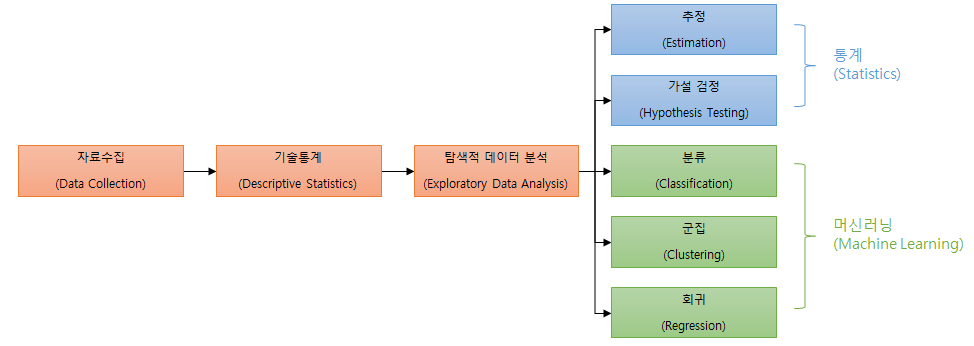
- ьєхЖ│ё(Statistics): ВХћВаЋ(Estimation), Ж░ђВёц Ж▓ђВдЮ(Hypothesis Testing)
- веИВІа вЪгвІЮ(Machine Learning): вХёвЦў(Classification), Жх░ВДЉ(Clustering), ьџїЖиђ(Regression)
import pandas as pd import numpy as np
[edit]
2 ВъљвБї ВѕўВДЉЖ│╝ Вцђв╣ё(Data Collection & Preparation) #
вЇ░ВЮ┤ьё░ ВЮйЖИ░[2]
- DBВЌљВёю вЇ░ВЮ┤ьё░ ВЮйЖИ░
- FileВЌљВёю вЇ░ВЮ┤ьё░ ВЮйЖИ░
- вгИВъљВЌ┤вАю DataFrame вДївЊцЖИ░
- JSON ьїїВІ▒ьЋўЖИ░
- HiveВЌљВёю вЇ░ВЮ┤ьё░ ВЮйЖИ░
[edit]
3 ЖИ░ВѕаьєхЖ│ё(Descriptive Statistics) #
ВЋё.. pythonВю╝вАю ьЋ┤ВЋ╝ ьЋўвѓў? вѓю SQLЖ│╝ ExcelВЮ┤ ьЏеВћг ьјИьЋўвІе вДљВЮ┤ВЋ╝..
вфЕВаЂ
- вЇ░ВЮ┤ьё░ВЮў ВЮ┤ьЋ┤вЦ╝ ВюёьЋ┤ ВІюЖ░ЂьЎћьЋўЖ│а ВџћВЋй
- вЇ░ВЮ┤ьё░ВЮў ьі╣Вё▒ в░Ј вХёьЈг ьїїВЋЁ
[edit]
12 В░ИЖ│аВъљвБї #
- Python-Tip
- ВѕўьЋЎ ЖИ░ьўИВЎђ ВЮўв»И
![[https]](/moniwiki/imgs/https.png) Python Flask вАю Ж░ёвІеьЋю REST API ВъЉВё▒ьЋўЖИ░
Python Flask вАю Ж░ёвІеьЋю REST API ВъЉВё▒ьЋўЖИ░
- Pyspark Start
- Big Data: On RDDs, Dataframes,Hive QL with Pyspark and SparkR-Part 3
- в│ЉвагВ▓ўвдг ВўѕВаю
![[http]](/moniwiki/imgs/http.png) Novelty and Outlier Detection
Novelty and Outlier Detection
- рёЉрЁАрёІрЁхрёірЁЦрєФ Numpy рёЅрЁЦрєФрёњрЁДрє╝рёЃрЁбрёЅрЁ« рёІрЁхрёњрЁбрёњрЁАрёђрЁх
- JDBC ВѓгВџЕ ВўѕВаю
- SciPy Cookbook
- ьїїВЮ┤ВЇг вЮ╝ВЮ┤вИївЪгвдгвЦ╝ ьЎюВџЕьЋю веИВІавЪгвІЮ/ВЋѕвЊюваѕВЋёВіц в«љвЪг , ВёИвЮ╝ Ж░ђВЮ┤вЈё ВДђВЮї/ьЋюв╣Џв»ИвћћВќ┤/9788968483394(8968483396)
- ьїїВЮ┤ВЇг вЮ╝ВЮ┤вИївЪгвдгвЦ╝ ьЎюВџЕьЋю вЇ░ВЮ┤ьё░ вХёВёЮ/ВЏеВіц В║ЉьѓцвІѕ ВДђВЮї/ьЋюв╣Џв»ИвћћВќ┤/9788968480478(8968480478)
- Think Stats/ВЋевЪ░ B. вІцВџ░вІѕ ВДђВЮї/ьЋюв╣Џв»ИвћћВќ┤/9788968486340
- ЖиИВЎИВЮў ЖИ░ьЃђ Ж▓ђВЃЅ..
 ЖИ░Ж│ёьЋЎВіхЖ░ювАа (ВХюВ▓ў)
ЖИ░Ж│ёьЋЎВіхЖ░ювАа (ВХюВ▓ў)
- Python Tip & Tech
- вфевЊа ьїїВЮ┤ВЇг ьћёвАюЖиИвъўвеИвЦ╝ ВюёьЋю 20Ж░ђВДђ ВІцВџЕВаЂВЮИ ьїїВЮ┤ВЇг вЮ╝ВЮ┤вИївЪгвдг
ВађвЈё ьїїВЮ┤ВёаВЮё в░░ВЏїв│╝вацЖ│а вѓ┤Ж░ђ ВЋїЖ│а Въѕвіћ ЖИ░ВѕаьєхЖ│ёвХђьё░ ВІюВъЉьЋўвацвІцЖ░ђ ьё▒ вДЅьўђ в▓ёваИвёцВџћ. RВЌљВёа ьЋюВцёВЮ┤вЕ┤ вљўвіћ Ж▓ЃВЮ┤ ьїїВЮ┤ВёаВЌљВёювіћ...сЁасЁа
Ж▓░ЖхГ вЇ░ВЮ┤ьё░ ВаёВ▓ўвдгвѓў ЖИ░ВѕаьєхЖ│ё, ВЮ╝в░ў ьєхЖ│ё вЊ▒ВЮђ RВЮё ВѓгВџЕьЋўЖ│а веИВІавЪгвІЮВЮ┤вѓў вћЦвЪгвІЮ Ж│аЖИЅВЮђ ьїїВЮ┤ВёаВЮё ВѓгВџЕьЋўвіћ Ж▓ЃВЮ┤ вДъВДђ ВЋіВЮёЖ╣ї ВІХВЮђ ВЃЮЖ░ЂВЮ┤ вЊГвІѕвІц. ВџћВдў... -- Ж╣ђВбЁьЌї 2021-07-23 21:41:47
Ж▓░ЖхГ вЇ░ВЮ┤ьё░ ВаёВ▓ўвдгвѓў ЖИ░ВѕаьєхЖ│ё, ВЮ╝в░ў ьєхЖ│ё вЊ▒ВЮђ RВЮё ВѓгВџЕьЋўЖ│а веИВІавЪгвІЮВЮ┤вѓў вћЦвЪгвІЮ Ж│аЖИЅВЮђ ьїїВЮ┤ВёаВЮё ВѓгВџЕьЋўвіћ Ж▓ЃВЮ┤ вДъВДђ ВЋіВЮёЖ╣ї ВІХВЮђ ВЃЮЖ░ЂВЮ┤ вЊГвІѕвІц. ВџћВдў... -- Ж╣ђВбЁьЌї 2021-07-23 21:41:47