-- Sample datatabase
SET NOCOUNT ON;
IF DB_ID('testparallel') IS NULL CREATE DATABASE testparallel;
GO
USE testparallel;
GO
-- Helper function GetNums
-- returns a sequence of integers of a requested size
IF OBJECT_ID('dbo.GetNums', 'IF') IS NOT NULL
DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@n AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT TOP (@n) n FROM Nums ORDER BY n;
GO
USE testparallel;
IF OBJECT_ID('dbo.T1') IS NOT NULL DROP TABLE dbo.T1;
IF OBJECT_ID('dbo.T2') IS NOT NULL DROP TABLE dbo.T2;
GO
CREATE TABLE dbo.T1
(
col1 INT NOT NULL,
col2 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT(0x)
);
CREATE UNIQUE CLUSTERED INDEX idx_cl_col1 ON dbo.T1(col1);
INSERT INTO dbo.T1 WITH(TABLOCK) (col1, col2)
SELECT n AS col1, n AS col2
FROM dbo.GetNums(1000000);
SELECT * INTO dbo.T2 FROM dbo.T1;
CREATE UNIQUE CLUSTERED INDEX idx_cl_col1 ON dbo.T2(col1);
GO
SELECT * FROM dbo.T1 JOIN T2 ON T1.col1 = T2.col1 WHERE T1.col2 <= 100;
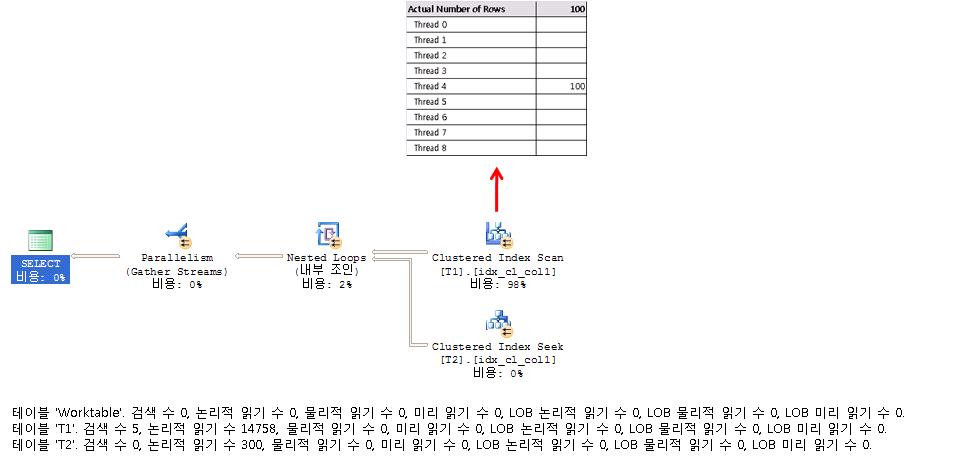
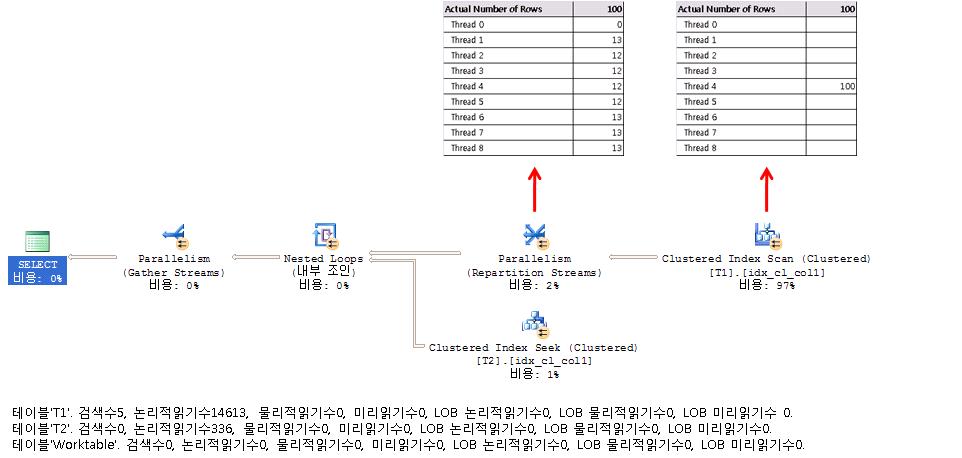
USE testparallel;
IF OBJECT_ID('dbo.Fact', 'U') IS NOT NULL DROP TABLE dbo.Fact;
IF OBJECT_ID('dbo.Dim1', 'U') IS NOT NULL DROP TABLE dbo.Dim1;
IF OBJECT_ID('dbo.Dim2', 'U') IS NOT NULL DROP TABLE dbo.Dim2;
IF OBJECT_ID('dbo.Dim3', 'U') IS NOT NULL DROP TABLE dbo.Dim3;
GO
CREATE TABLE dbo.Dim1
(
key1 INT NOT NULL CONSTRAINT PK_Dim1 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Dim2
(
key2 INT NOT NULL CONSTRAINT PK_Dim2 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Dim3
(
key3 INT NOT NULL CONSTRAINT PK_Dim3 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Fact
(
key1 INT NOT NULL CONSTRAINT FK_Fact_Dim1 FOREIGN KEY
REFERENCES dbo.Dim1,key2 INT NOT NULL CONSTRAINT FK_Fact_Dim2 FOREIGN KEY
REFERENCES dbo.Dim2,
key3 INT NOT NULL CONSTRAINT FK_Fact_Dim3 FOREIGN KEY REFERENCES dbo.Dim3,
measure1 INT NOT NULL,
measure2 INT NOT NULL,
measure3 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x),
CONSTRAINT PK_Fact PRIMARY KEY(key1, key2, key3)
);
INSERT INTO dbo.Dim1(key1, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 20 + 1
FROM dbo.GetNums(100);
INSERT INTO dbo.Dim2(key2, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 10 + 1
FROM dbo.GetNums(50);
INSERT INTO dbo.Dim3(key3, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 40 + 1
FROM dbo.GetNums(200);
INSERT INTO dbo.Fact WITH (TABLOCK)
(key1, key2, key3, measure1, measure2, measure3)
SELECT N1.n, N2.n, N3.n,
ABS(CHECKSUM(NEWID())) % 1000000 + 1,
ABS(CHECKSUM(NEWID())) % 1000000 + 1,
ABS(CHECKSUM(NEWID())) % 1000000 + 1
FROM dbo.GetNums(100) AS N1
CROSS JOIN dbo.GetNums(50) AS N2
CROSS JOIN dbo.GetNums(200) AS N3;
GO
SELECT * FROM dbo.Fact AS F JOIN dbo.Dim2 AS D2 ON F.key2 = D2.key2 JOIN dbo.Dim3 AS D3 ON F.key3 = D3.key3 WHERE D2.attr1 <= 3 AND D3.attr1 <= 2;
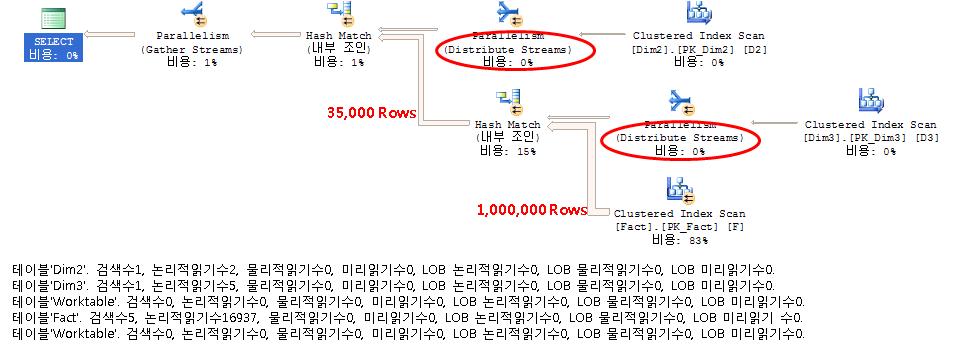
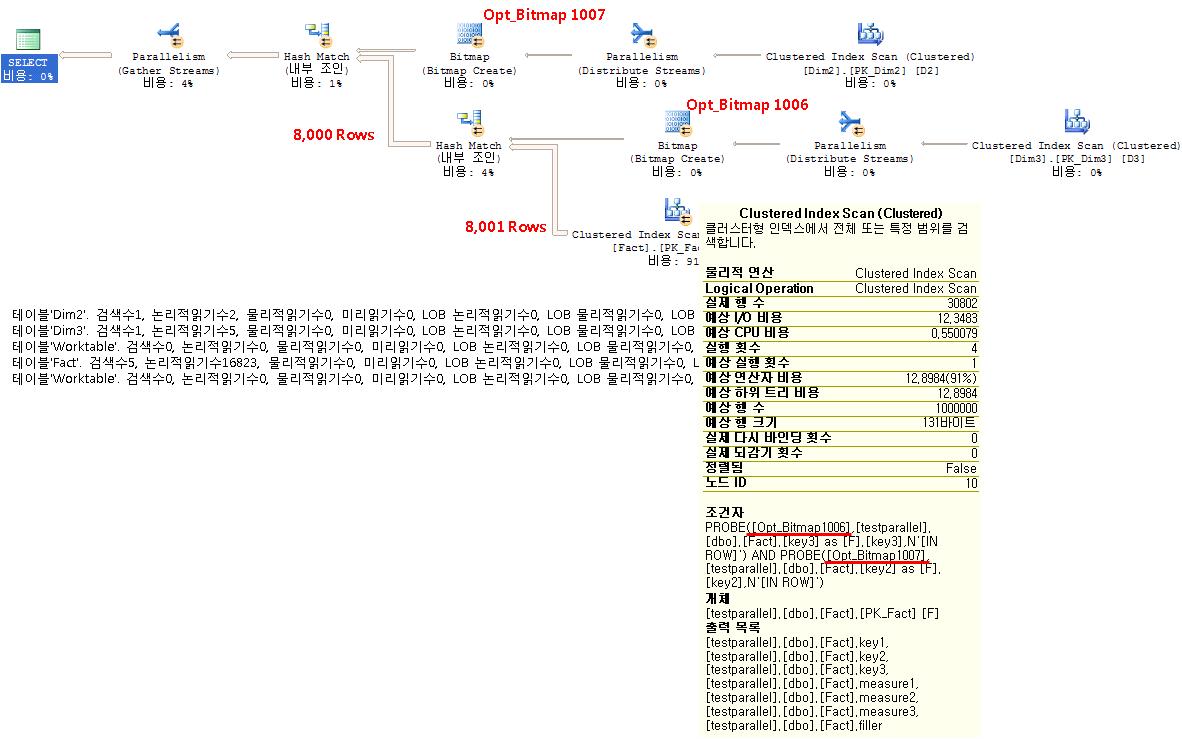
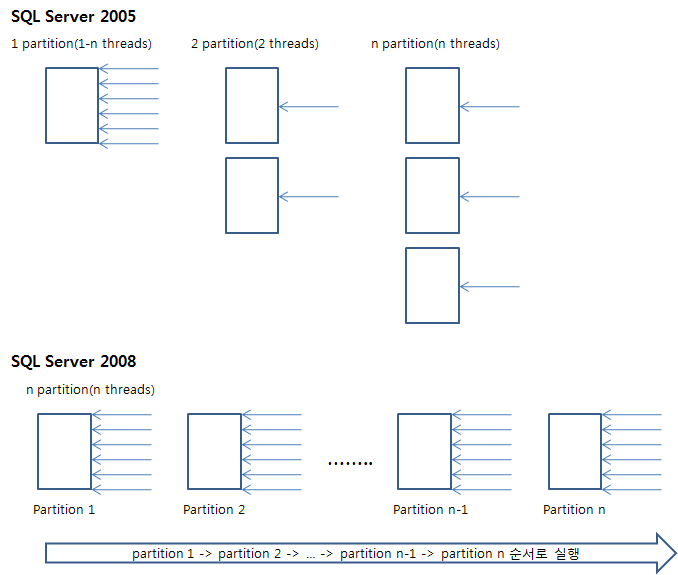
USE testparallel;
IF OBJECT_ID('dbo.PartitionedTable', 'U') IS NOT NULL
DROP TABLE dbo.PartitionedTable;
IF EXISTS(SELECT * FROM sys.partition_schemes WHERE name = 'PS1')
DROP PARTITION SCHEME PS1;
IF EXISTS(SELECT * FROM sys.partition_functions WHERE name = 'PF1')
DROP PARTITION FUNCTION PF1;
GO
CREATE PARTITION FUNCTION PF1 (INT)
AS RANGE LEFT FOR VALUES (250000, 500000, 750000);
CREATE PARTITION SCHEME PS1
AS PARTITION PF1 ALL TO ([PRIMARY]);
CREATE TABLE dbo.PartitionedTable
(
col1 INT NOT NULL,
col2 INT NOT NULL,
filler BINARY(100) DEFAULT(0x)
) ON PS1(col1);
CREATE UNIQUE CLUSTERED INDEX idx_col1 ON dbo.PartitionedTable(col1) ON PS1(col1);
INSERT INTO dbo.PartitionedTable WITH (TABLOCK) (col1, col2)
SELECT n, ABS(CHECKSUM(NEWID())) % 1000000 + 1
FROM dbo.GetNums(1000000);
SELECT * FROM dbo.PartitionedTable WHERE col1 <= 500000 ORDER BY col2;
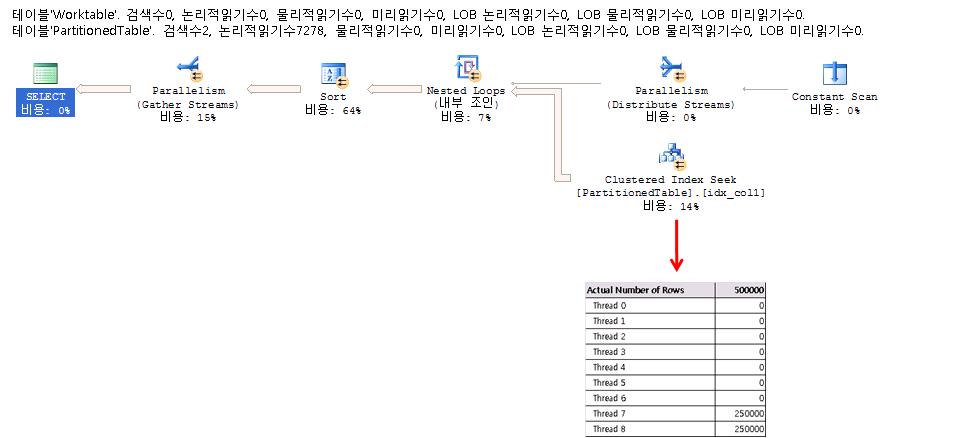
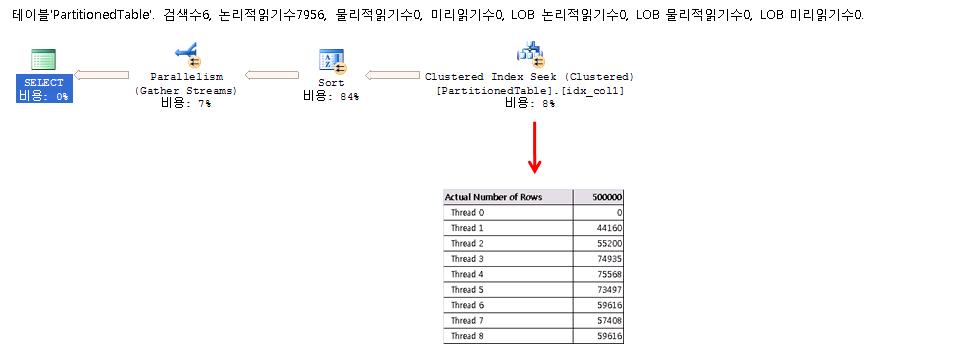
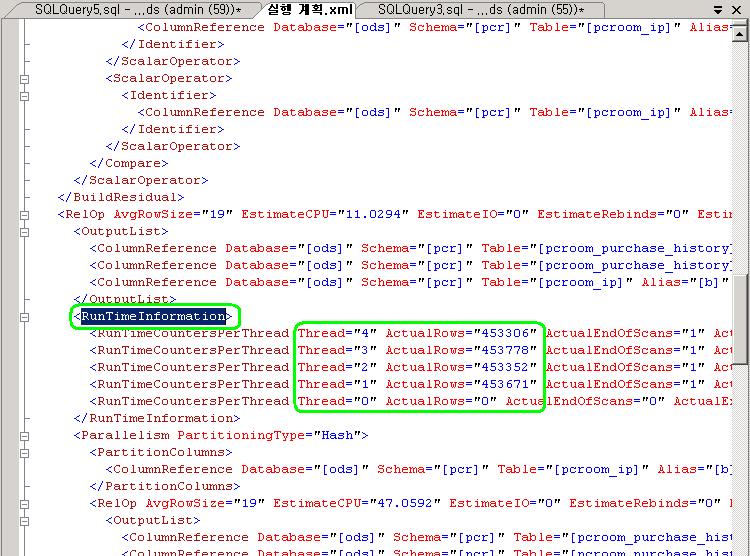
DBCC TRACEON (3604); -- Show DBCC output DBCC SHOWWEIGHTS; -- Show the settings /* 결과 DBCC Opt Weights CPU: 1.000000 IO: 1.000000 SPID 81 */
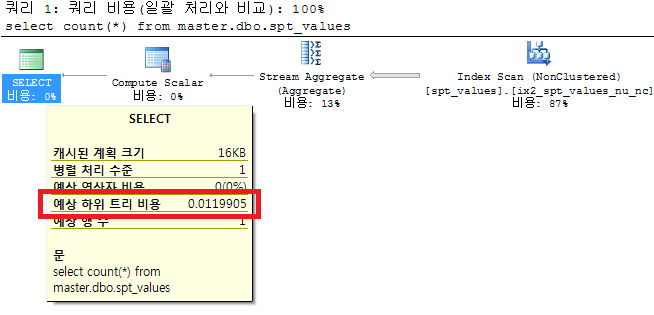
select count(*) from master.dbo.spt_values
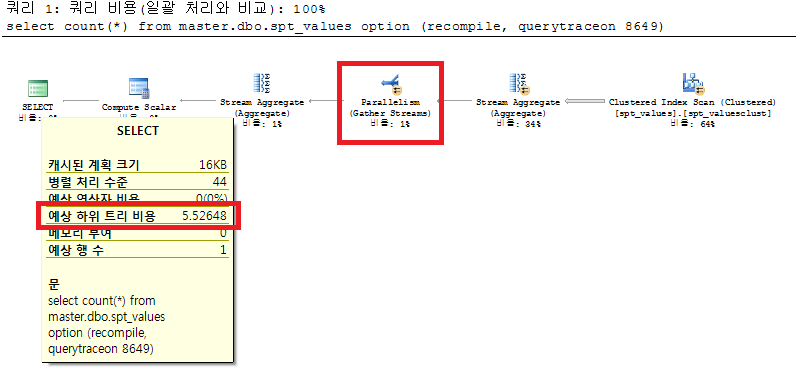
DBCC FREEPROCCACHE DBCC SETCPUWEIGHT(10000); go select count(*) from master.dbo.spt_values option (recompile, querytraceon 8649) -- 옵션은 꼭 필요하다. go DBCC SETCPUWEIGHT(1); -- 원래대로 해놓자. DBCC SETIOWEIGHT(1); --io에도 가중치를 줄 수 있다. go
DBCC FREEPROCCACHE DBCC SETCPUWEIGHT(10); DBCC SETIOWEIGHT(10000); go select count(*) from master.dbo.spt_values option (recompile, querytraceon 8649) go DBCC SETCPUWEIGHT(1); -- Default CPU weight DBCC SETIOWEIGHT(1); go
DBCC TRACEOFF (3604);
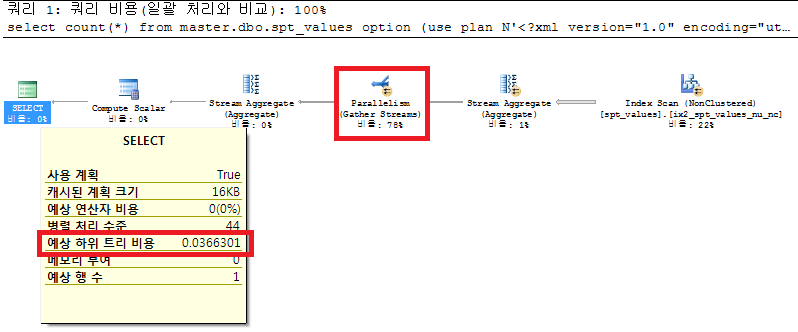
select count(*) from master.dbo.spt_values option (use plan N'<?xml version="1.0" encoding="utf-16"?> ... ... ... --소스가 길어서 아래의 source_01.txt로 첨부하였다.source_01.txt (새창에서 열림)
set nocount on
set statistics io off
declare
@bdt char(8)
, @edt char(8)
, @p int
, @sql varchar(4000)
set @bdt = '20110928'
while (@bdt <= '20300301')
begin
set @edt = convert(char(8), dateadd(dd, 1, @bdt), 112)
set @p = $partition.파티션함수(@bdt)
set @sql = '
alter table 테이블명
rebuild partition = ' + convert(varchar, @p) + '
with (data_compression = page)'
exec (@sql)
print @sql
--print @bdt + ', ' + @edt
set @bdt = @edt
end
![[http]](/moniwiki/imgs/http.png) Forcing a Parallel Query Execution Plan(http://sqlblog.com/blogs/paul_white/archive/2011/12/23/forcing-a-parallel-query-execution-plan.aspx)
Forcing a Parallel Query Execution Plan(http://sqlblog.com/blogs/paul_white/archive/2011/12/23/forcing-a-parallel-query-execution-plan.aspx) Understanding and Controlling Parallel Query Processing in SQL Server 2008Understanding and Using Parallelism in SQL Server(http://www.simple-talk.com/sql/learn-sql-server/understanding-and-using-parallelism-in-sql-server/)
Understanding and Controlling Parallel Query Processing in SQL Server 2008Understanding and Using Parallelism in SQL Server(http://www.simple-talk.com/sql/learn-sql-server/understanding-and-using-parallelism-in-sql-server/)![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")